자소서만 쓰다가는 내가 가지고 있던 지식들을 다 까먹을 거 같아서 근근히 실습을 진행할려고 한다..
자소서 쓰기 싫은 건 아니구?
그래서 참여하게 된 추석 맞이 추석 선물 수요량 예측 AI 대회!
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 한글 글씨체 깨짐
mport matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
# 데이터 불러오기
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
submission = pd.read_csv('./sample_submission.csv')train.head()
target은 수요량이고, feature을 살펴봤을 때 추석까지 남은 기간 (주), 쇼핑몰 구분, 가격(원), 프로모션 여부, 도시유형, 쇼핑몰 유형, 선물유형으로 이루어져있다.
대부분 feature들이 범주형 변수인 것을 확인할 수 있었다. 다만, 각 관측값의 경우 정확한 명칭, 도시이름, 지역명을 알 수가 없었다.
def resumertable(df):
print(f'데이터셋 형상 : {df.shape}')
summary = pd.DataFrame(df.dtypes, columns = ['데이터 타입'])
summary = summary.reset_index()
summary = summary.rename(columns = {'index':'피처'})
summary['결측값 개수'] = df.isnull().sum().values
summary['고유값 개수'] = df.nunique().values
summary['첫번째 값'] = df.loc[0].values
summary['두번째 값'] = df.loc[1].values
summary['세번째 값'] = df.loc[2].values
return summary
resumertable(train)
모든feature의 경우 결측값의 없었다. 프로모션 여부의 경우 이진형 범주형이고 슈핑몰과 선물 유형의 경우에는 상당히 많은 고유값의 개수를 가지고 있었다.
다음은 종속변수인 수요량의 분포를 확인해봤다.
sns.displot(train['수요량'])
plt.show()
대다수의 값이 0 근처에 몰려 있는 것을 확인했다. 분포가 한쪽으로 쏠려있어서 로그 변환을 고려했다.
다음은 각 feature들을 시각화 해보았다.
sns.barplot(x='추석까지 남은 기간(주)',y='수요량',data=train)
추석까지 남은 기간이 길수록 수요량이 미세하게 증가한 것을 볼 수 있다. 아마도 다들 미리미리 사놓은 듯 하다..
sns.barplot(x='프로모션 여부',y='수요량',data=train)

프로모션의 경우, 프로모션을 한 상품일 수록 더욱더 수요량이 증가한 것을 볼 수 있다. (어찌보면 당연한 것..)
sns.barplot(x='지역 유형',y='수요량',data=train)
지역의 경우 지역별로 차이가 들쑥날쑥하여 크게 경향성 및 상관성이 있어보이지는 않는다.
sns.barplot(x='쇼핑몰 유형',y='수요량',data=train)
쇼핑몰 유형의 경우 쇼핑몰 유형 3이 가장 높은 수요량을 보이는 것을 볼 수 있었다. 도시, 선물유형도 시각화해보았지만 크게 의미가 없어보였다. 혹여 가격이 싸면 더 많은 수요가 있지 않을까 해서 가격과 수요량의 산점도를 그려보았지만, 큰 의미는 없어보였다.
sns.scatterplot(x='가격(원)',y='수요량',data=train)
다음은 각 수치형 feature들의 상관계수를 살펴보았다.
plt.figure(figsize = (8,8)) sns.heatmap(train.corr(), annot = True, cmap = 'Blues') plt.show()
프로모션 여부 > 가격 > 추석까지 남은 기간(주) 순으로 상관계수 값이 나타났지만 그 값이 너무 작으므로 큰 의미는 없어 보였다.
2. 파생변수
이번 대회에서 파생변수는 만들기 쉽지 않아보였다. 관측값이 대부분 유형 1,2,3, 등으로 나타났기 때문에 의미를 가진 파생변수를 만들기 쉽지 않았다. 그래도 선물의 유형 같은 경우에는 대분류(스팸류, 고기류) 로 생성해보았지만 성능이 너무 구려서.. 이 과정은 생략했다.
3. 데이터 전처리
범주형 변수가 많았기 때문에 label encoding과 one-hot encoding을 고려했다. 그 중 모델을 부스팅 모델을 고려했기 때문에 label encoding을 진행했다. 그런데... label encoding을 이용한 후 학습한 결과 정말 너무나도 성능이 개구리게 나왔다... (RMSE가 130대에서 300대로 커져버림..)
따라서 인코딩 과정도 과감하게 생략했다.
4. 모델 생성
4-1 catboost+optuna (RMSE 132.027)
일단 단순하게 feature 유형이 범주형이 많기 때문에 catboost 모델이 가장 성능이 좋지 않을까 생각했고 pycaret을 이용해서 확인해 본 결과 catboost가 가장 좋은 성능을 보인것을 확인했다.
from catboost import CatBoostRegressor
import xgboost as xgb
import optuna
from optuna.samplers import TPESampler
from sklearn.model_selection import train_test_split
from optuna import Trial
import sklearn
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import StackingRegressor
from supervised.automl import AutoML
from pycaret.regression import *
# ID 제거 및 타킷값 분리
X_train = train.drop(['ID','수요량'],axis=1)
y_train = train['수요량']
test = test.drop(['ID'],axis = 1)
# valid 데이터 만들기
X_train,X_valid,y_train,y_valid = train_test_split(X_train,y_train,test_size = 10, random_state=10)# AUTO ML을 이용
sup = setup(X_train,target=y_train)
comp = compare_models(sort='RMSE')
그 다음 optuna를 이용해서 하이퍼파라미터 튜닝을 진행했다.
# cat 변수 가져오기
cat_features_tr = [f for f in X_train.columns if X_train[f].dtype=='object']
cat_features_te = [f for f in test.columns if test[f].dtype=='object']
for i in cat_features_tr:
X_train[i] = X_train[i].astype("category")
for i in cat_features_te:
test[i] = test[i].astype("category")# optuna 이용하기
# optuna 이용해서 최적 파라미터 구하기
# regressor임!
def objectives_reg(trial: Trial, X_train,y_train,X_valid,y_valid):
param = {
'iterations':trial.suggest_int("iterations", 1000, 20000),
'od_wait':trial.suggest_int('od_wait', 500, 2300),
'learning_rate' : trial.suggest_uniform('learning_rate',0.01, 1),
'reg_lambda': trial.suggest_uniform('reg_lambda',1e-5,100),
'subsample': trial.suggest_uniform('subsample',0,1),
'random_strength': trial.suggest_uniform('random_strength',10,50),
'depth': trial.suggest_int('depth',1, 15),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf',1,30),
'leaf_estimation_iterations': trial.suggest_int('leaf_estimation_iterations',1,15),
'bagging_temperature' :trial.suggest_loguniform('bagging_temperature', 0.01, 100.00),
'colsample_bylevel':trial.suggest_float('colsample_bylevel', 0.4, 1.0),
'eval_metric' : 'RMSE'
}
# 학습 모델 생성
model = CatBoostRegressor(**param)
cat_model = model.fit(X_train,y_train, eval_set=[(X_valid,y_valid)],early_stopping_rounds=100, verbose=False,cat_features = cat_features_tr ) # 학습 진행
# 모델 성능 확인
score = sklearn.metrics.mean_squared_error(cat_model.predict(X_valid), y_valid,squared=True)
return score머신러닝 모델의 경우 숫자만을 인식하기 때문에 반드시 인코딩 과정이 필요하다. 그러나 인코딩 과정 시 성능이 개 구려지므로, cat_features옵션을 이용했다. (인코딩을 하지 않고 cat_features옵션을 이용하게 되면 catboost 모델이 알아서 인코딩을 해준다.)
# RMSE가 최소가 되는 방향으로 학습을 진행
study_rn = optuna.create_study(direction='minimize', sampler=TPESampler())
study_rn.optimize(lambda trial : objectives_reg(trial, X_train,y_train,X_valid,y_valid), n_trials = 40)
cat_params = study_rn.best_trial.params
cat_model = CatBoostRegressor(**cat_params,random_state= 42) #optuna를 통해 가장 좋은 하이퍼파라미터를 선택
cat_model.fit(X_train, y_train,cat_features = cat_features_tr) #모델 적합
cat_pred_y = cat_model.predict(test)
submission['수요량'] = cat_pred_y이렇게 해서 RMSE 값 132.027이 나왔다.
4-2 Autogluon (RMSE 109.587)
from autogluon.tabular import TabularDataset, TabularPredictor# autogluon 학습을 위한 데이터 형태로 변환
train_auto = TabularDataset(train.drop('ID',axis=1))
test_auto = TabularDataset(test)
predictor = TabularPredictor(label="수요량",eval_metric='rmse')
# 각각의 모델의 훈련 성능을 평가할 수 있음
ld_board = predictor.leaderboard(train_auto, silent=True)
ld_board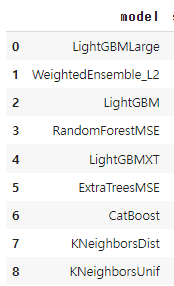
이번에 새롭게 알게된 auto ml의 라이브러리.. 사실 이전에는 pycaret을 이용하는 건만 알았는데 autogluon을 알게되었다.. 굉장한 녀셕이었다... (ㅎㄷㄷ)
확인해 본 결과 가장 좋은 성능은 WeightEnsembel_L2 였고 이것을 이용해서 학습을 진행했다.
model_to_use = predictor.get_model_best()
model_pred = predictor.predict(test_auto, model=model_to_use)
submission['수요량'] = model_pred
submission.head()그 결과 RMSE 109.587이 나왔다. (등수로는 3n로 마무리)
후기)
추석 동안 간만에 재미있게 참여한 대회였다. 등수 하나하나 올리는 거에 쾌감도 느꼈고.. 다만 아직까지 많이 부족하구나 느낀다. 상위권 코드를 분석해보니 하이퍼파라미터를 조정하는 것이 역시나 매우 중요하다는 것을 알았다.
조금 아쉬운 건 파생변수, 전처리 과정이 생략되어버렸다는 점.. 물론 성능이 너무 구려져서 버리긴 했지만... 왜 그렇게 되는지 너무 궁금하다...